
Low overhead, on-demand Kubernetes clusters deployed on CI Workers Nodes with KIND
How to test Kubernetes artifacts like Helm charts and YAML manifests in your CI pipelines with a low-overhead, on-demand Kubernetes cluster deployed with KIND - Kubernetes in Docker.Containers have become very popular for packaging applications because they solve the dependency management problem. An application packaged in a container includes all necessary run-time dependencies so it becomes portable across execution platforms. In other words, if it works on my machine it will very likely also work on yours.
Automated testing is ubiquitous in DevOps and we should containerize our tests for exactly the same reasons as we containerize our applications: if a certain test validates reliably on my machine it should work equally well on yours, irrespective of which libraries and tools you have installed natively.
Testing with Containers
The following figure illustrates a pipeline (or maybe two, depending on how you organize your pipelines) where the upper part builds and packages the application in a container and the lower part does the same with the tests that will be used to validate the application. The application is only promoted if the container-based tests pass.
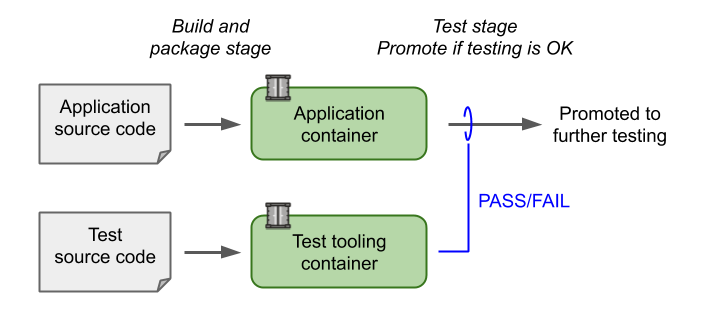
If we assume that the application is a network-attached service where black-box testing can be executed through network connectivity, a setup like the one above is easily implemented by:
- Build application and test containers, e.g. using ‘docker build …’
- Start an instance of the application container attached to a network, e.g. with ‘docker run …’
- Start an instance of the test container attached to the same network as the application, e.g. with ‘docker run …’
- The exit code of the test container determines the application test result
This is illustrated in the figure below.
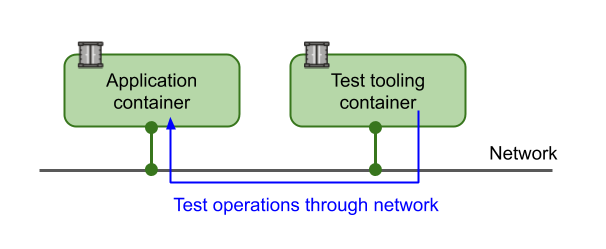
Steps 2 through 4 outlined above can also be described in a docker-compose definition with two services, e.g. (the test container is configured with the application network location through an environment variable):
version: '3.7'
services:
test:
image: test-container:latest
environment:
APPLICATION_URL: http://application:8080
depends_on:
- application
application:
image: application:latest
ports:
- 8080:8080A test using the two containers can now be executed with:
docker-compose up --exit-code-from test
Testing Kubernetes Artifacts in the CI Pipeline
The process described above works well for tests at ‘container level’. But what if the output artifacts of the CI pipelines includes Kubernetes artifacts, e.g. YAML manifests or Helm charts, or needs to be deployed to a Kubernetes cluster to be validated? How do we test in those situations?
One option is to have a Kubernetes cluster deployed which the CI pipelines can deploy to. However, this gives us some issues to consider:
- A shared cluster which all CI pipelines can deploy to basically becomes a multi-tenant cluster which might need careful isolation, security, and robustness considerations.
- How do we size the CI Kubernetes cluster? Most likely the cluster capacity will be disconnected from the CI worker capacity i.e. they cannot share compute resources. This will result in low utilization. Also, we cannot size the CI cluster too small because we do not want tests to fail due to other pipelines temporarily consuming resources.
- We might want to test our Kubernetes artifacts against many versions and configurations of Kubernetes, i.e. we basically need N CI clusters available.
We could also create a Kubernetes cluster on demand for each CI job. This requires:
- Access to a cloud-like platform where we can dynamically provision Kubernetes clusters.
- Our CI pipelines have the necessary privileges to create infrastructure which might be undesirable from a security point-of-view.
For some test scenarios we need a production-like cluster and we will have to consider one of the above solutions, e.g. characteristics tests or scalability tests. However, in many situations, the tests we want our CI pipelines to perform can be managed within the capacity of a single CI worker node. The following section describes how to create on-demand clusters on a container-capable CI worker node.
On-Demand Private Kubernetes Cluster with KIND
Kubernetes-in-Docker (KIND) is an implementation of a Kubernetes cluster using Docker-in-Docker (DIND) technology. Docker-in-docker means that we can run containers inside containers and those inner containers are only visible inside the outer container. KIND uses this to implement a cluster by using the outer container to implement Kubernetes cluster nodes. When a Kubernetes POD is started on a node it is implemented with containers inside the outer node container.
With KIND we can create on-demand and multi-node Kubernetes clusters on top of the container capabilities of our CI worker node.
A KIND Kubernetes cluster :
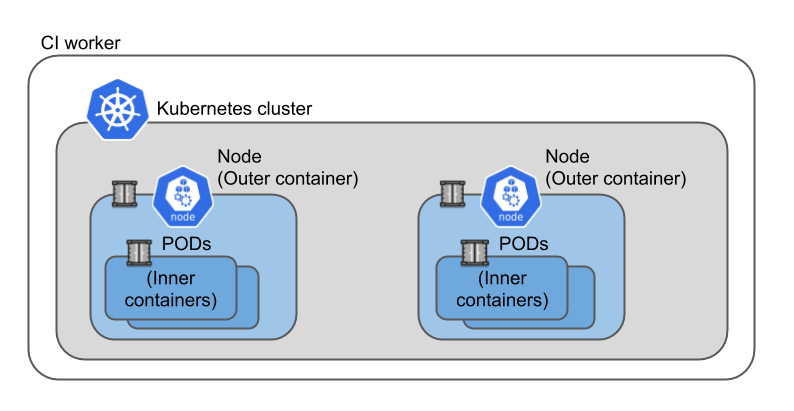
The cluster capacity will obviously be limited by CI worker node capacity, but otherwise the Kubernetes cluster will have many of the capabilities of a production cluster, including HA capabilities.
Let’s demonstrate how to test an application deployed with Helm to a KIND cluster. The application is the k8s-sentence-age application which can be found on Github, including a Github action that implements the CI pipeline described in this blog. The application is a simple service that can return a random number (an ‘age’) between 0 and 100 and also provides appropriate Prometheus compatible metrics.
Installing KIND
KIND is a single executable, named kind, which basically talks to the container runtime on the CI worker. It will create an (outer) container for each node in the cluster using container images containing the Kubernetes control-plane. An example of installing kind as part of a Github action can be found here.
Creating a Cluster
With the kind tool our CI pipelines can create a single node Kubernetes cluster with the following command:
kind create cluster --wait 5m
We can also create multi-node clusters if we need them for our tests. Multi-node clusters require a configuration file that lists node roles:
# config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker With the above configuration file we can create a three-node cluster with the following command:
kind create cluster --config config.yaml
We can specify which container image the KIND Kubernetes nodes should use and thereby control the version of Kubernetes:
kind create cluster --image "kindest/node:v1.16.4"
With this we can easily test compatibility against multiple versions of Kubernetes as part of our CI pipeline.
Building Application Images and Making Them Available to KIND
The example k8s-sentences-age application is packaged in a container named ‘age’ and the tests for the application are packaged in a container named ‘age-test’. These containers are built in the usual way as follows:
docker build -t age:latest ../app docker build -t age-test:latest .
We can make the new version of these images available to our KIND Kubernetes nodes with the following command:
kind load docker-image age:latest kind load docker-image age-test:latest
Loading the images onto KIND cluster nodes copies the image to each node in the cluster.
Running a Test
Our pipeline will deploy the application using its Helm chart and run the tests against this deployed application instance.
Deploying the application with the application Helm chart means that we not only test the application container when deployed to Kubernetes, but we also validate the Helm chart itself. The Helm chart contains the YAML manifests defining the application Kubernetes blueprint and this is particularly important to validate - not only against different versions of Kubernetes, but also in various configurations, e.g. permutations of values given to the Helm chart.
We install the application with the following Helm command. Note that we override the Helm chart default settings for image repository, tag and pullPolicy such that the local image used.
helm install --wait age ../helm/age \ --set image.repository=age \ --set image.tag=latest \ --set image.pullPolicy=Never
The test container is deployed using a Kubernetes Job resource. Kubernetes Job resources define workloads that run to completion and report completion status. The job will use the local ‘age-test‘ container image we built previously and will connect to the application POD(s) using the URLs provided in environment variables. The URLs reference the Kubernetes service created by the Helm chart.
apiVersion: batch/v1
kind: Job
metadata:
name: component-test
spec:
template:
metadata:
labels:
type: component-test
spec:
containers:
- name: component-test
image: age-test
imagePullPolicy: Never
env:
- name: SERVICE_URL
value: http://age:8080
- name: METRICS_URL
value: http://age:8080/metrics
restartPolicy: Never </code>The job is deployed with this command:
kubectl apply -f k8s-component-test-job.yaml
Checking the Test Result
We need to wait for the component test job to finish before we can check the result. The kubectl tool allows waiting for various conditions on different resources, including job completions. i.e. our pipeline will wait for the test to complete with the following command:
kubectl wait --for=condition=complete \ --timeout=1m job/component-test
The component test job will have test results as part of its logs. To include these results as part of the pipeline output we print the logs of the job with kubectl and with a label selector to select the job pod.
kubectl logs -l type=component-test
The overall status of the component test is read from the job POD field .status.succeeded and stored in a SUCCESS variable as shown below. If the status indicates failure the pipeline terminates with an error:
SUCCESS=$(kubectl get job component-test \-o jsonpath='{.status.succeeded}')if [ $SUCCESS != '1' ]; then exit 1; fiecho "Component test successful"
The full pipeline can be found in the k8s-sentences-age repository on Github.
It is worth noting here that starting a test job and validating the result is what a helm test does. Helm test is a way of formally integrating tests into Helm charts such that users of the chart can run these tests after installing the chart. It therefore makes good sense to include the tests in your Helm charts and make the test container available to users of the Helm chart. To include the test job above into the Helm chart we simply need to add the annotation shown below and include the YAML file as part of the chart.
...
metadata:
name: component-test
annotations:
"helm.sh/hook": test When a KIND Cluster Isn’t Sufficient
In some situations a local Kubernetes cluster on a CI worker might not be ideal for your testing purposes. This could be when:
- Unit tests have call functions e.g. use classes from the application. In this case application and tests are most likely a single container which could be executed without Kubernetes.
- Components tests involve no Kubernetes-related artifacts. If the example shown above did not have a Helm chart to test, the docker-compose solution would have been sufficient.
- Tests involve a characteristics test, e.g. measuring performance and scalability of your application. In such situations you would need infrastructure which is more stable with respect to capacity.
- Integration tests that depend on other artifacts cannot easily be deployed in the local KIND cluster, like a large database with customer data.
- Functional, integration or acceptance tests require the whole ‘application’ to be deployed. Some applications might not fit within the limited size of the KIND cluster.
- Tests which have external dependencies, e.g. cloud provider specific ingress/load balancing, storage solutions, key management services etc. In some cases these can be simulated by deploying e.g. a database on the KIND cluster and in other cases they cannot.
However, there are still many cases where testing with a KIND Kubernetes cluster is ideal, e.g. when you have Kubernetes-related artifacts to test like a Helm chart or YAML manifests, and when an external CI/staging Kubernetes cluster involves too much maintenance overhead or is too resource in-efficient.
Published: Apr 24, 2020
Updated: Mar 26, 2024
