How we explain the Continuous Delivery story
A developer that pushes their changes and goes on a celebratory walk to the water cooler is done. But, they’re not done done, their changes have yet to be thoroughly tested, added to future release notes, properly peer reviewed and more. These are pains we want to rid the software industry of, and here’s how we do it.
At Praqma (company acquired by Eficode in 2019), we help our customers embrace and implement Continuous Delivery. To help them set their sights on tangible goals, we’ve developed a Continuous Delivery storyline. We depict a workflow with, at its core, the removal of waste, and the automation of development processes. This lays the foundation for Continuous Delivery, the means to release changes safely, quickly and sustainably.
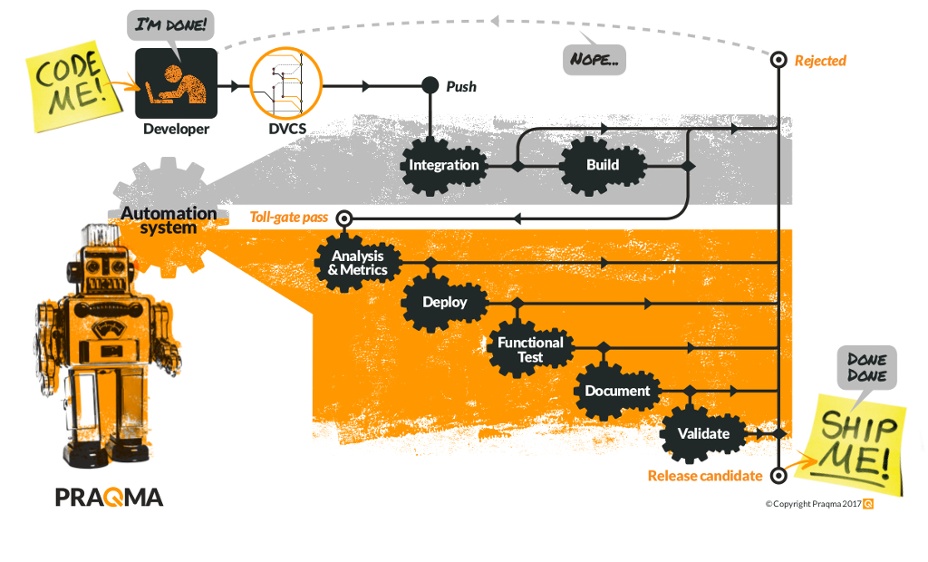
While you’re at the water cooler
Up first is automated integration. With the CI server relying on local merges and toll-gate tests, we keep the mainline pristine. Automating integration allows you to integrate smaller changes more often, avoiding dreadful merge hells.
The change undergoes increasingly rigorous testing after integration. Our confidence in it increases as it travels further down the pipeline. As the goal is to fail as soon as possible, we prefer running fast tests early. Metrics are a good start, as they quickly gauge the code’s health. Thresholds help prevent technical debt, while the data facilitates the code reviews down the line.
Up next is automatic deployment to a production-like environment. This tests the deployment process and allows for extensive testing in a realistic environment. Once these tests pass, we’re confident enough to start preparing for a potential release.
We start by automatically generating documentation and release notes. Relevant work items are also flagged for the team’s weekly code review. We now have a release candidate, ready to ship, without lifting a finger.
Optimizing the pipeline
Unless you spend an awful long time at the water cooler, you’ll want to optimize your pipeline. The goal is shortening feedback loops. With shorter loops come less wait states, task switching, etc. However, wanton automation won’t get you shorter loops. The key is streamlining first, automating after.
Here’s a few thoughts to keep in mind when improving your pipeline:
- If something is difficult, do it often
- Automating wasteful processes is waste
- The throughput of a pipeline is dictated by its biggest bottleneck
- If your pipeline never breaks, it’s probably broken
Making deliberate, data-driven improvements, we inch closer to the bigger picture. From thereon out, the real fun begins. Having closed the loop, we can develop right next to the customer, and experiment with A-B testing, canary rollouts, etc.
Published: Feb 7, 2018
Updated: Jun 1, 2021
