
Automating an Automation Server
Job DSL or scripted/declarative pipelines are becoming the standard when it comes to defining jobs in Jenkins. Now we need a similar
solution to maintain Jenkins itself.
Jenkins can be installed through native system packages, Docker, or run standalone by any machine with a Java Runtime Environment (JRE) installed. But configuring Jenkins is a tedious process, no matter how you choose to run it, and the more plugins you use the more tedious it gets. Given that there are more than 1400 plugins available it’s easy to reach an unmanageable state.
Both Jenkins and its plugins require manual configuration, by default available only via UI. The Jenkins Configuration as Code plugin (JCasC) allows us to manage such configuration via human readable configuration files.
Why did we develop (yet another!) Jenkins plugin?
Configuration as code is not a new concept and Jenkins already provides a way to automate its deployment e.g. by introducing support for init scripts written in Groovy. The problem is that it requires you to know Groovy and understand the inner workings of Jenkins and its plugins. It also mixes scripts with configuration and doesn’t honor one of our important principles of separating the “what” from the “how.”
One specific example is JenkinsAsCodeReference developed at Praqma. I worked with a customer who wanted to introduce this approach and I loved it from the very beginning. I didn’t have much experience with Jenkins at the time, so having a way to preserve old configuration, without the need of saving non-readable xml or taking screenshot of existing setup for documentation, was a big relief. And it allowed me to experiment and implement without fear.
JenkinsAsCodeReference is now being used by a number of companies, but it has issues. It forces you to use Docker and it also handles deployment of Jenkins. Redeployment is time-consuming and the actual configuration is mixed with Groovy scripts. This started to get annoying so we decided to come up with a new, better solution that would provide the same features (and much more) but would be easier to maintain, faster, and could be used in various (not only Docker) scenarios.
By we I mean me and other Praqma developers, later joined by CloudBees engineers, and by better solution I mean a plugin.
While preparing the prototype of the plugin we found existing ones. CloudBees engineers and regular Jenkins users were trying to do exactly the same thing. We saw this as a great opportunity for collaboration, so we got in touch with CloudBees and found that our visions, goals and motivations were very much aligned.

And now we’re working together on making this the Configuration as Code solution for Jenkins.
What are the benefits of Jenkins Configuration as Code?
The goal of the plugin is to do for Jenkins configuration what Job DSL once did for jobs. Move it to code! We also want to learn from the pains that were involved in making Job DSL. That is, for the plugin to succeed, it has to support as many plugins as possible out of the box, without needing to write glue code for each plugin. Let’s remind ourselves that there is (much) more than 1000 of them. Not ALL of them require some sort of global configuration, but the number that need to be supported by the Jenkins Configuration as Code plugin is still quite high.
It is a challenge and we already know we won’t be able to support all of the plugins. Some glue code and a number of Pull Requests to make the plugins support our requirements will be needed, but we believe it’s worth it.
Jenkins Configuration as Code does not help you deploy Jenkins - you will still need to do that your favorite way using containers, Kubernetes, native system package, Ansible or the like, but as soon as you’re about to start Jenkins, JCasC will be there to save you. There’ll be no more manual editing of the Jenkins global configuration under Manage Jenkins after deployment.
Once you have prepared your configuration file Jenkins can be configured automatically when it starts. You can restore your Jenkins easily - within seconds. You can also reuse the same file to configure multiple Jenkins instances, or you can spin up a local instance to test your changes before you make them part of the production environment.
If you decide to keep your configuration file in some VCS e.g. Git repository - which I believe you should - you can keep track of changes in the Jenkins global configuration. This makes it possible to quickly restore a previous configuration if the new one proves to be unsatisfying. It also makes it easy to compare and trace changes when something is broken.
Jenkins Configuration as Code is the last missing piece in the puzzle for you to completely manage your Jenkins instance as code. You can now have your infrastructure as code.
Why I think JCasC is simply better
One of the many challenges we set ourselves was to mimic Jenkins UI in a configuration file as much as possible. We didn’t want to have to scroll through long documentation pages to find out how to configure the Mailer plugin or Artifactory Server details. And, of course, we didn’t want to implement separate solutions for each plugin either. So, if you have some Jenkins management experience, writing such a file will come naturally to you. But don’t worry if it doesn’t, we’re not the enemies of documentation, we still allow it to generate itself! Furthermore, it will be generated based on your actual Jenkins setup and you can access it directly on your own server.
The configuration files for the global Jenkins configuration should be human readable. We don’t want it to be language specific, it can’t require specific knowledge, and it should support comments. These are the reasons we chose YAML. It is easy to write and because of available schema it is also possible to get support within your IDE and verify your configuration without running Jenkins instance.
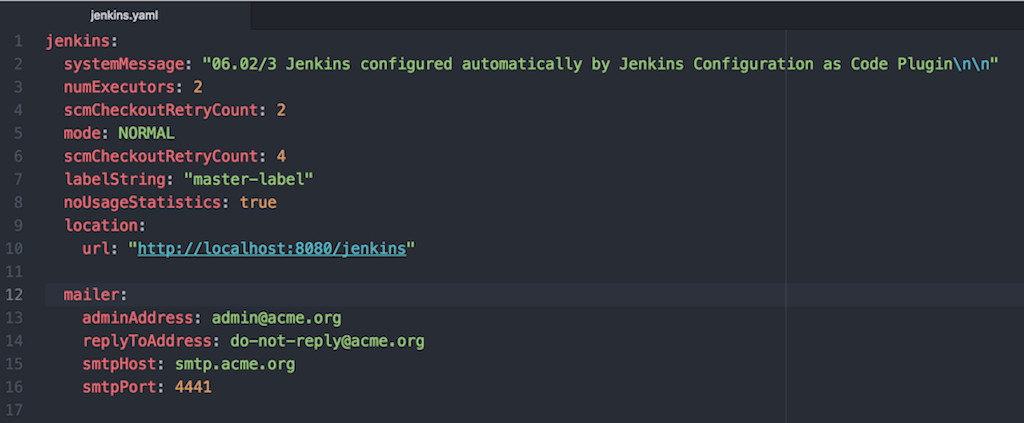
And, most importantly, once you introduce the change in your configuration file you’ll be able to reload it without restarting Jenkins. No more time consuming redeployment!
Want to help?
I mentioned the involvement of CloudBees engineers in the plugin, but there’s a little more to that story. We’ve presented the concept at a number of meet-ups and CloudBees made some noise about it during FOSDEM at the beginning of February. The reaction has been great - we’re are already getting external contributors. The Pull Requests and feature ideas are coming!
You can get involved too - the more PRs the better. Feel free to create issues with features or bugs. We don’t just want to solve our problems, we want to solve yours too!
https://github.com/jenkinsci/configuration-as-code-plugin is the place to go now!
Published: Feb 27, 2018
Updated: Mar 26, 2024

