How to automatically deploy Helm charts to a Kubernetes cluster
Helm charts lifecycle management is a manual task. Helmsman allows you to automate your Helm charts lifecycle management using declarative configuration files.
Helm packages Kubernetes applications as reusable, customizable and shareable packages called “charts”. Helmsman adds a layer of abstraction around Helm and allows users to declaratively define a desired state of their Helm charts in a Kubernetes cluster.
Why we created Helmsman
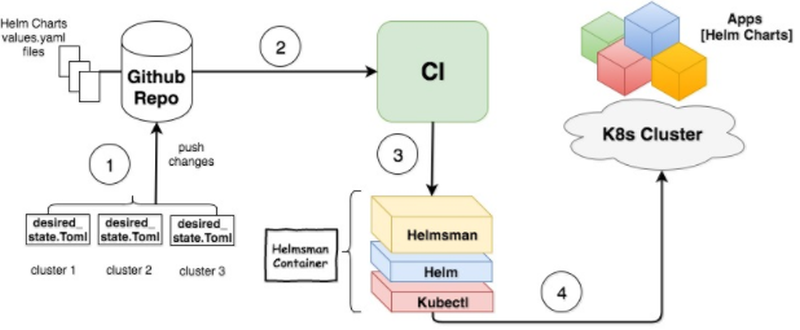
While working on deploying Atlassian products in a Kubernetes cluster for a customer, we started by creating Kubernetes manifest files for the needed Kubernetes objects. We needed to automate the deployment of these objects in the cluster everytime we push changes in our git repo. We came up with a custom script in our CI pipeline to do this for us. The operations we wanted to support included: creating, deleting, upgrading and moving Kubernetes objects to different namespaces. As we progressed in the project, it quickly turned out that the script became complex and difficult to maintain. It needed to be updated every time we added a new Kubernetes object. We started using Helm as it helped us group multiple Kubernetes objects into one unit; a “chart”. Then the CI script got a bit simpler, but still needed to be updated regularly with new charts. And what if we need to replicate this setup for another customer? We will need to replicate and customize the CI script.
We needed a more dynamic and less interactive way of doing this. Then, came the idea of defining a “desired state”, -describing what charts and where we want them to exist in the cluster- and a tool that is smart enough to make sure this state is achieved. Something like infrastructure as code, but for Helm charts (Kubernetes apps). When we change the desired state, the tool can understand what changes we need and make them happen for us. This way, we only need to maintain our desired state and let the tool handle the logic of how it’s implemented. We called this tool “Helmsman” since it works as autopilot for your Kubernetes cluster.
How does Helmsman work?
Helmsman gets its directions to navigate from a declarative file called Desired State File (DSF) maintained by the user (Kubernetes admin) and is usually version controlled. DSFs follow a specification which allows user to define how to connect to a Kubernetes cluster, what namespaces to use/create, what Helm repos to use for finding charts, and what instances (aka releases) of the chart to be installed/deleted/rolled back/upgraded and with what input parameters.
Helmsman interprets your wishes from the DSF and compares it to what’s running in the designated cluster. It is smart enough to figure out what changes need to be applied to make your wishes come true without maintaining/storing any additional information anywhere.
A simple DSF looks like the example below (which works with minikube):
[metadata]
org = "example.com"
# using a minikube cluster
[settings]
kubeContext = "minikube"
[namespaces]
[namespaces.staging]
protected = false
[namespaces.production]
protected = true
[helmRepos]
stable = "https://kubernetes-charts.storage.googleapis.com"
incubator = "http://storage.googleapis.com/kubernetes-charts-incubator"
[apps]
[apps.artifactory]
name = "artifactory-prod" # should be unique across all apps
description = "production artifactory"
namespace = "production"
enabled = true
chart = "stable/artifactory"
version = "6.2.0" # chart version
valuesFile = "../my-artificatory-production-values.yaml"
[apps.jenkins-test]
name = "jenkins-test" # should be unique across all apps
description = "test release of jenkins, testing xyz feature"
namespace = "staging"
enabled = true
chart = "stable/jenkins"
version = "0.9.1" # chart version
valuesFile = "../my-jenkins-testing-values.yaml" </code>What’s on offer?
In addition to deploying Helm charts from code, Helmsman gives you the following features:
- Simple declarative format: using Toml format which does not care about whitespaces! Hurray!
- It is portable: it can be used to manage charts deployments on any Kubernetes cluster. The only dependencies it needs are helm and kubectl.
- Plan, View, apply: you can run Helmsman to generate and view a plan with/without executing it.
- Multiple usage options: it can be used as a binary tool or a docker image.
- Idempotent: As long your desired state file does not change, you can execute Helmsman several times and get the same result.
- Continue from failures: In the case of partial deployment due to a specific chart deployment failure, fix your Helm chart and execute Helmsman again without needing to rollback the partial successes first.
- Secrets passing: from environment variables to charts.
- K8S secrets and Helm charts fetching: from private cloud buckets. Currently both AWS and GCS are supported.
- Protected releases/namespaces: against accidental commits.
For more details on these features, refer to the documentation.
Open Source
Helmsman has been helping us, and we are happy to share it with the community. It is open source and we welcome all forms of contributions and feedback. The project is hosted on Github.
Published: Mar 1, 2018
Updated: Mar 26, 2024
