An automated release train, operated directly from my shell?
Imagine a workflow so sophisticated that you couldn’t break the integration branch even if you tried. Imagine being able to manage all of the issues, promotions, and deploys without leaving your terminal.
More than a year ago, we presented a story about how we operate our git workflow directly from the command line using a handful of useful aliases. Since then, we’ve taken these aliases to a self-contained Git extension named Git phlow (pronounced /fləʊ/ like in flow). The Git extension is available for Brew and Chocolatey packages (install instructions here).
The Phlow encourages you to tie all your commits to tasks. This gives you so many benefits that once you’ve tried it, you won’t remember how you ever lived without it.
Beware: The Phlow is not related to the blog post “The Git Flow - a Successful Branching Strategy,” which made the internet unsafe a couple of years back. The Phlow was created to remedy all the flaws in that approach. The Phlow implements a pure release train, representing the simplest, coolest Git branching strategy.
But maybe the coolest feature of the Phlow is that it’s designed to be automated. The pipeline is a first-class citizen in the Phlow.
Why the need for an automated flow?
Behind the desire for an automated flow lies a subtle critique of the Pull-Request-based workflows that seem to have taken over the world, particularly since the success of GitHub and Atlassian. The Pull-Request approach works well when only one benevolent dictator and a few trusted lieutenants guard the repository while everyone else submits Pull-Requests. However, it’s even used extensively in teams where everyone contributes to the code equally.
You could argue that a Pull-Request represents unplanned work from the perspective of the person being asked to do the commit, and it represents queued work from the developer's perspective. You can even say it’s a paradigm that values control or policy over quality. Some say Pull-Requests are good because they help teach the people involved. This is obviously beneficial, but it could be accomplished as easily during development through paired programming or simply chatting with colleagues. So, we must assume that as a quality gate, pull-requests stop faulty code from reaching the integration branch through validation.
When we say we’d like an automated flow, we’re referring to the process where the software being developed has a verifiable definition of done and that we have implemented that definition as a pipeline. So, we find testing if the developer’s code change can be verified in the pipeline to be more natural.
Automatically. So we need a robot.
The robot approach
The software development process is LEAN. It resembles the process of optimizing a factory floor more than the process of building a building or a bridge. We’re in pursuit of a flow, and if it’s not optimized, we will continuously improve it.
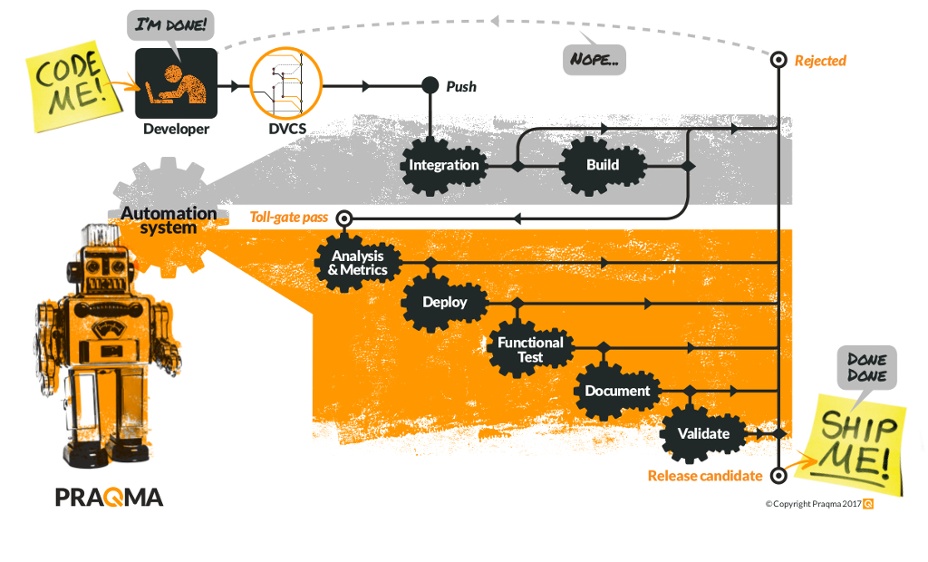
The Continuous Integration process (the grey area) is triggered automatically on new commits and is optimized for speed. It integrates the code into the master branch. The Continuous Delivery process (orange area) is also triggered automatically. It implements the complete definition of done and strives to verify a true release candidate. If something goes wrong, it means the software isn’t done yet.
As you can see from the picture, we have put validation after we have had the robot do all the verification. There’s no need to spend time on validation, even if it’s not verified.
The three git commands
The approach utilized by the Phlow is really simple. It builds on Git branches and naming conventions and isn’t dependent on a specific vendor technology - it’s just Git.
Seen from the developer’s terminal, it’s really just three more git commands:
git workon 321
git wrapup
git deliverThe logic is that you use git workon followed by the number of the issue you want to work on. This will establish your entire setup locally; a dedicated branch to work on, named after the issue’s heading, ties to the issue (currently, GitHub Issues or Jira are supported), making the issue a work in progress.
When the work is done locally, the developer uses git wrapup. It will add and remove files that were changed in the workspace to the index. The commit contains a message that automatically closes the issue by referencing a keyword when it enters the origin/master.
The next thing you do is git deliver, which pushes your local branch to origin but prefixes the branch name with a keyword (by default, we use ready/....). The CI server is looking for this, and when it finds it, the process kicks into action.
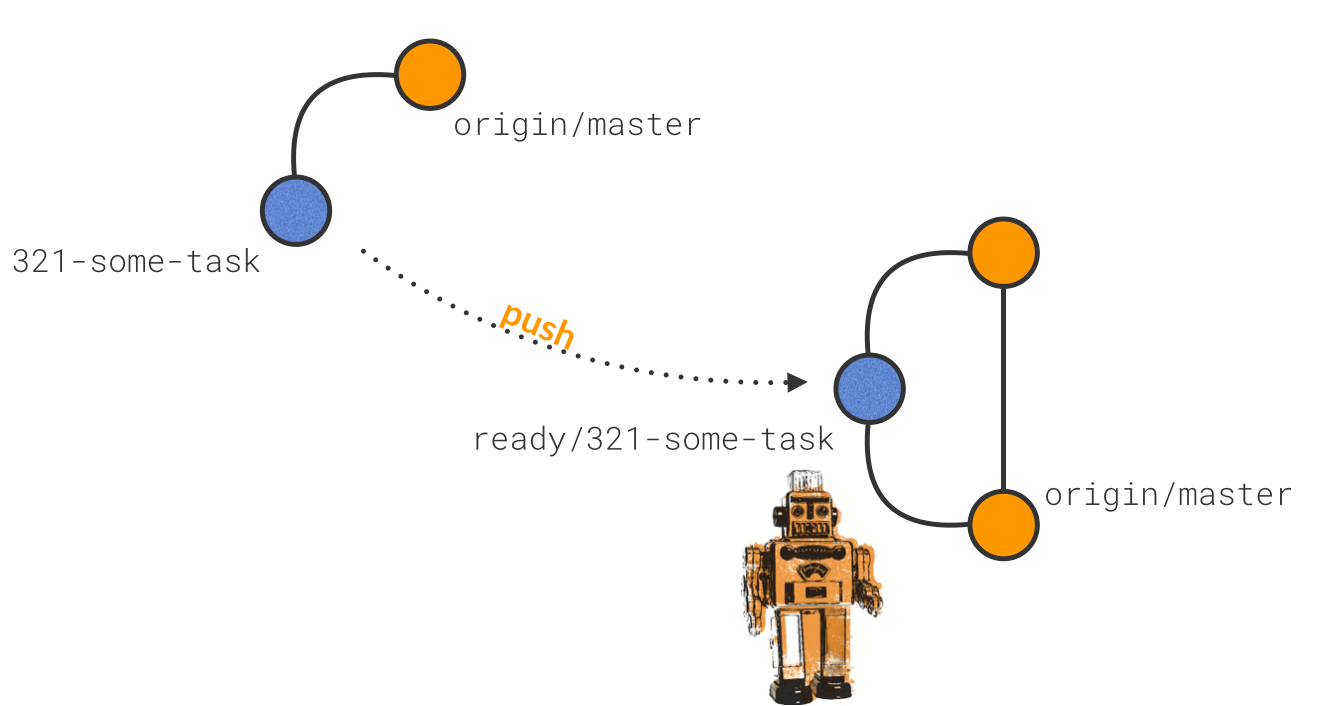
The robot is looking for “ready” branches
The release train
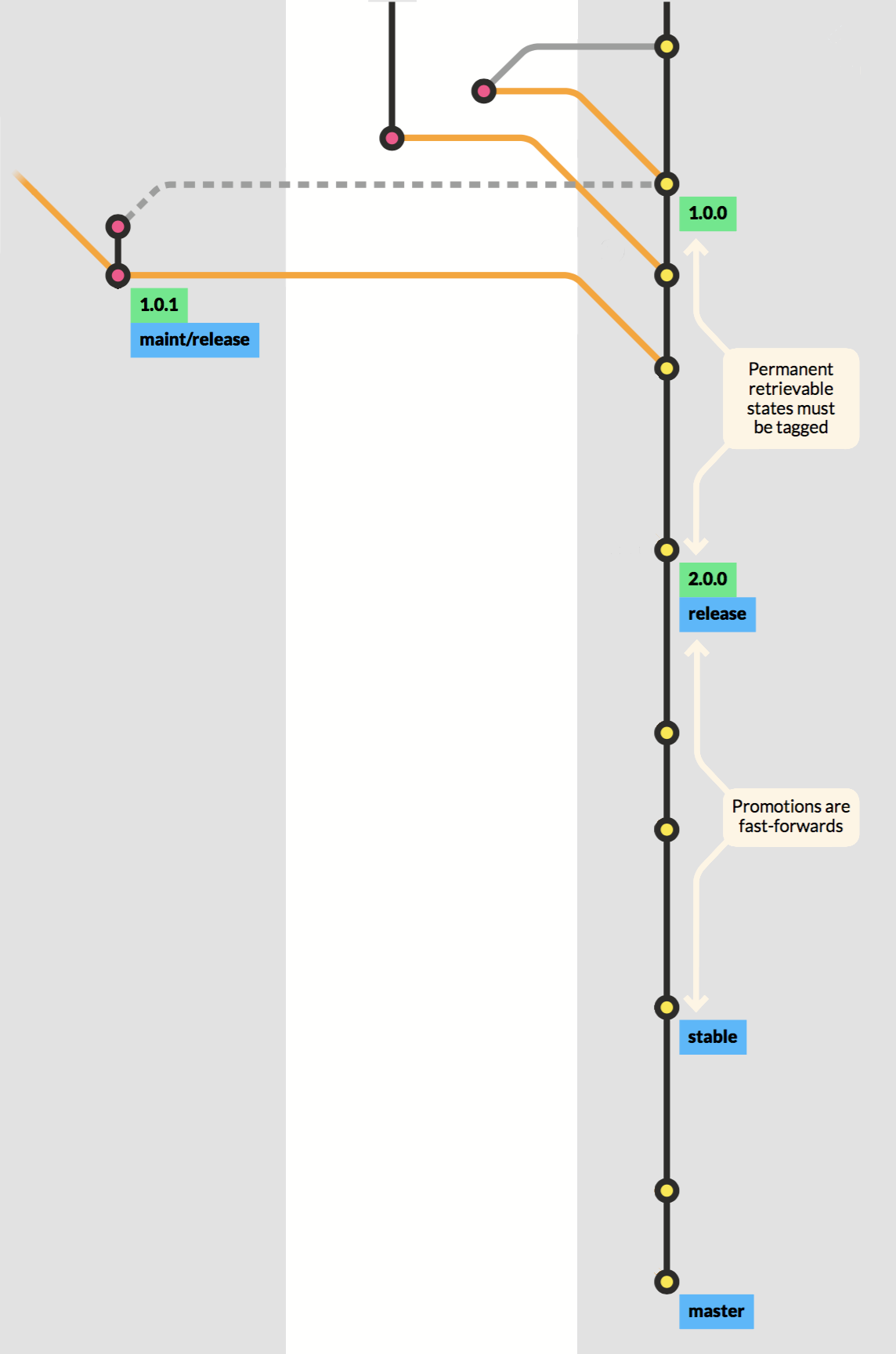
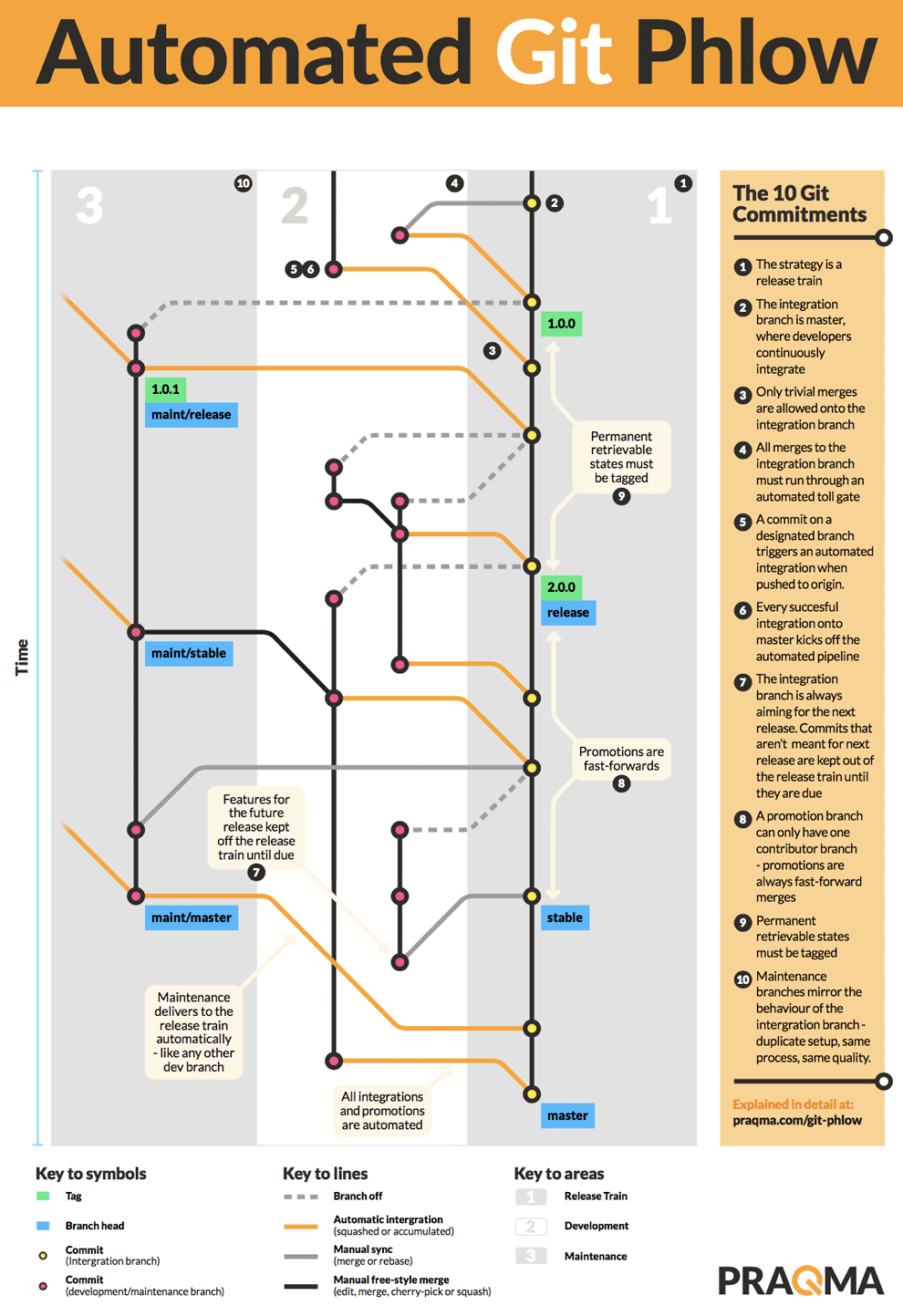
The only long-lived branch in the setup is master. This is “the release train”. If you want to get your code to production, you need to get it onto master - there’s no other way. During your work, you might want to indicate several levels of promotion. You can do that by using more branches, provided that they are restricted to fast-forwards only. It’s simple to achieve this. If you set up a rule that any promotion branch can only be fed from one other branch, it’s guaranteed to be fast-forward merges. In reality, it’s just an easy way to implement a floating label. So the master forwards to stable, which delivers to release. If you need permanent retrievable states, such as your historic releases, you must tag them - maybe even using signed tags.
From the release train's perspective, all branches look the same. The orange line in the master indicates that the process is automated. It can be a really simple case of workon, wrapup, and delivery, or it can be a case of a branch with a longer lifespan. It can even be a maintenance branch, which also turns out to be like any other development branch, except that the input is guarded using the same automated processes. It’s a micro-setup of the grander scheme - same pipeline, same quality - only it’s allowed to create maintenance releases to production. But, when changes made here need to go to the release train, they’ll follow the same procedure as if it was a simple branch - because that’s essentially what it is.
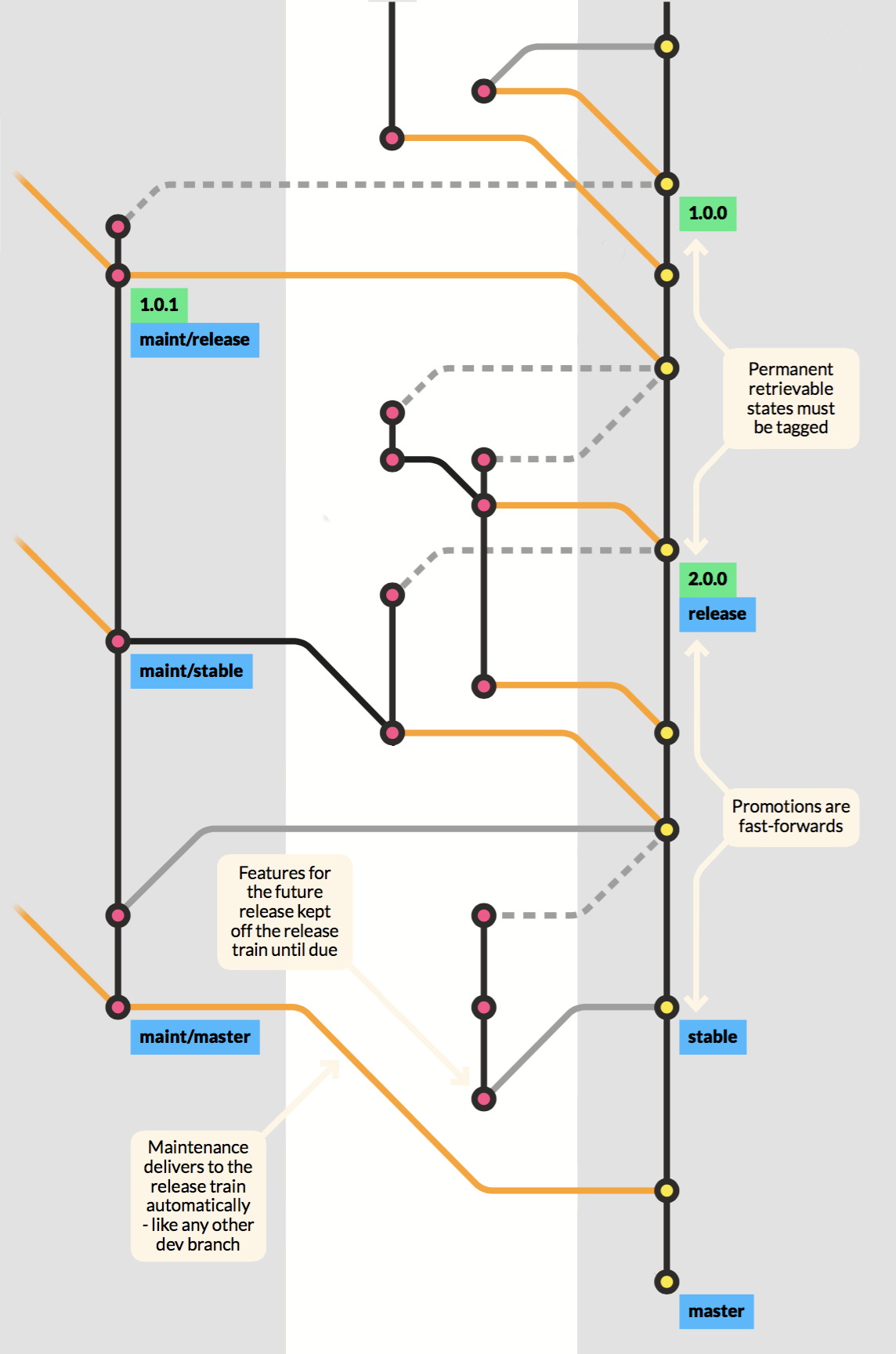
The automated integration gives the developers all the freedom they could wish for. They can utilize the full potential of Git, pushing, sharing, and collaborating on any branch they want. They can even reuse branches if they’re relevant, typically if an issue is reopened. The maintenance branch can continue to develop like any other branch. If it diverges from the master, and manual work is required to sort out merge conflicts or errors, it will be dealt with on an intermediate development branch in the development scope where it can be integrated automatically. When order is restored on a maintenance branch, the following deliveries can run automatically and directly to the master branch again. If a branch is not contributing to the next upcoming release, it has no business on the master branch, but of course, it can still keep in sync so that a future integration will not contain any surprises.
By following only ten simple commitments when you work in Git, you can have a branching strategy to support a software project of any size. And the git-phlow extension supports the Phlow out of the box. If you are using Jenkins, we’ve even made it easy to set up the whole automation using the pretested integration plugin. This is updated in the most recent release to support the Jenkins Pipelines.
The poster
We have made a poster - just write to us if you want one to hang in your office. It makes life so much easier.
Published: Oct 30, 2017
Updated: Aug 31, 2023
